
Functional Domain Driven Design: Simplified

Domain-Driven Design (DDD) simplifies the development and maintenance of complex software applications. However, two seminal books on the topic, Domain-Driven Design and Domain-Driven Design Distilled focus on an object-oriented implementation.
How can we translate the tactical patterns of DDD into a functional programming paradigm? This article will show you how I do it in TypeScript and the many simplifications and benefits. Let’s begin with a refresher on DDD.
Domain Driven Design
Domain-Driven Design focuses on business rules, business language, and business problems as the primary focus of software design. Instead of primarily designing software in architectural layers (e.g. database, data transfer objects, models, controllers, views), it focuses on building software with discrete domains or bounded contexts (e.g. billing, authentication, insurance sales, insurance claims, etc.)
DDD aligns our software architecture along the axis of most significant change; the business generates requests for changes to implement new business rules implemented in the domain. Focusing solely on software layers may produce greater code reuse, but reuse inhibits the ability to respond to changing business requirements. If both the Sales and Claims domain use an Insurance Policy entity, then a change on behalf of the sales team could inadvertently create a bug for the claims team. In DDD, we would make a separate SalesPolicy entity and a PolicyClaim entity, thus decoupling these two business domains in the codebase.
Domain-Driven Design splits its patterns into two categories: strategic patterns and tactical patterns. The strategic patterns are the easiest to reuse in any language, framework, and programming paradigm. They are universal aspects of software design.
However, the tactical patterns in DDD are tightly coupled to an object-oriented programming style and influenced by the capabilities of languages prevalent during DDD’s conception. These tactical patterns are where we will apply a functional approach to DDD and modify, remove, or create new tactical patterns.
Before we move into Functional implementations of tactical DDD patterns, let’s review the strategic patterns in DDD. Feel free to skip ahead if you are already familiar with these concepts.
Strategic DDD Patterns
These patterns govern the overall approach to your code and even your system architecture. They are relevant regardless of the language, framework, or paradigm. Since there is already a wealth of information about these patterns, we will only briefly cover some of the most crucial strategic patterns.
Bounded Context
A Bounded Context is a conceptual boundary in designing a system wherein the meaning of business terms is ubiquitous and consistent. For example, we may have the concept of a Policy entity in insurance. However, different teams in the business will have different interpretations of a policy, i.e. the sales team, the claims team, and the actuarial team will all assign the Policy entity different meanings.
By creating a bounded context in our design, we can effectively isolate each domain from the other. I use the term bounded context (context) and domain interchangeably throughout this article.
Context Map
Context mapping is how we identify, understand, and communicate the Contexts/Domains in our system. You will often identify common entities in context mapping — an important tenet of DDD is that we do not attempt to remove or share common entities between contexts. Instead, we allow each context to maintain its implementation and version of the data within its domain.
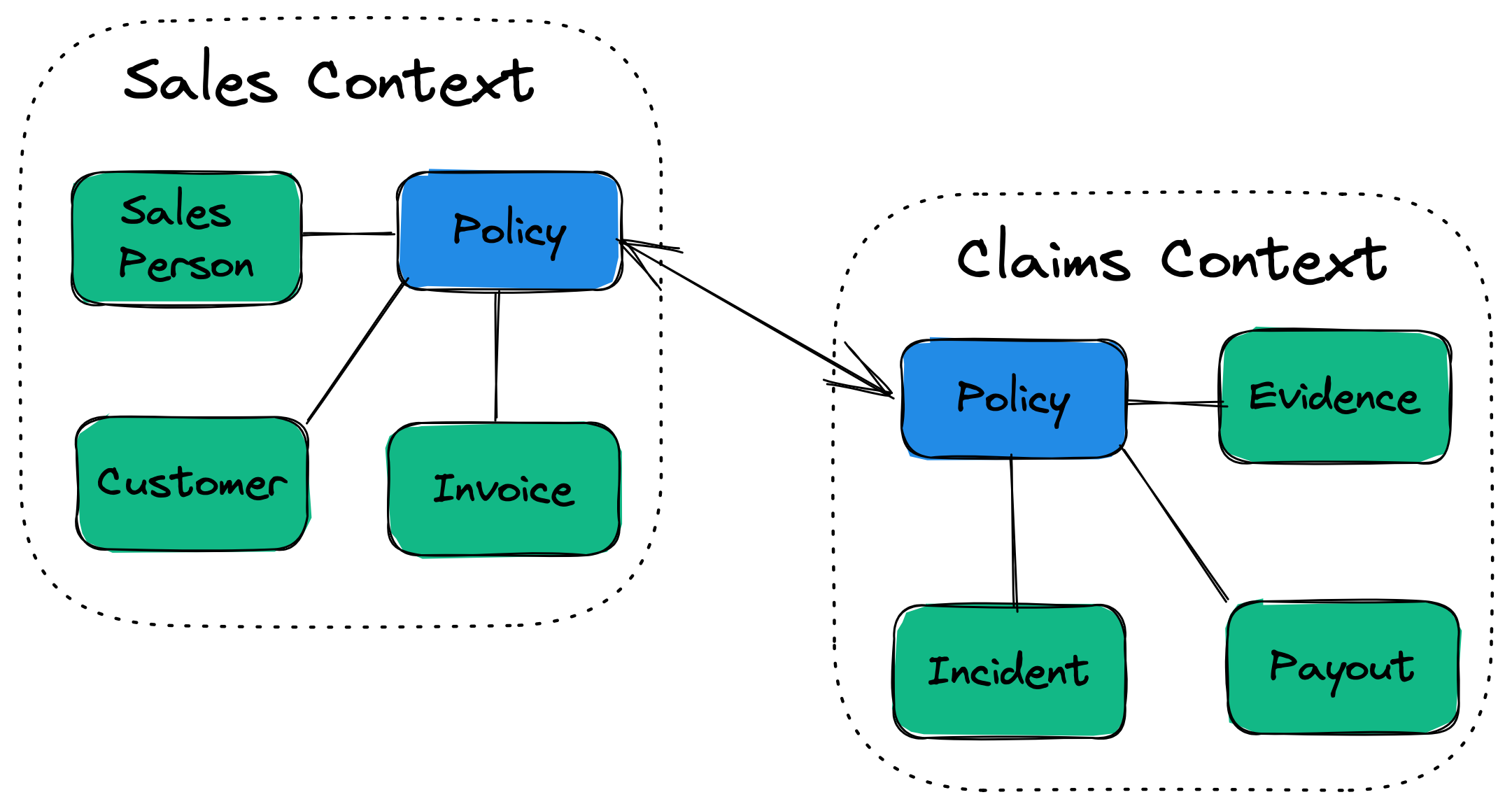
Anti-corruption Layer
In the above diagram, the "claims context" would implement an anti-corruption layer to adapt the incoming policy data into the format and structure meaningful to the "claims context". This pattern prevents details of the upstream entity from leaking into the downstream context and adds some protection against upstream changes.
Functional shortcomings in OOP DDD
Much of Classical DDD refers to methods of correctly allocating behaviour to the correct entity, aggregate root, domain service, or value object. Many of its rules aim to give DDD practitioners confidence in correctly distributing behaviour amongst various classes in their implementation.
However, Functional Domain Driven Design (fDDD) does not share these problems as data and behaviour are uni-directionally coupled rather than bi-directionally. That is to say that entities in Functional Programming cannot have their own behaviour but instead couples functions to data in the form of parameter types.
Any number of functions can use entities, but functions can only use entities matching their type signature.
Let's take stock of the Classical DDD concepts we have abandoned in fDDD:
Aggregate Root: In fDDD, transactions are bound to the Controller
Value Object: In fDDD, values are just literal values
Service: In fDDD, this is most closely related to the Controller
Domain Service
Factories
Functional DDD Tactical Patterns
It’s time to consider the practical implementation of DDD’s Tactical Patterns within a Functional Programming paradigm. We have two layers within these patterns: a Functional Core and an Imperative Shell.
The Functional Core implements tactical patterns using only Pure Functions. This layer is where we implement the bulk of our business rules since Pure Functions provide us with the greatest degree of predictability, reliability, testability, and changeability.
In the Imperative Shell, we want to use tactical patterns that help us coordinate between our systems and our business rules. For example, code in the imperative shell may be responsible for retrieving necessary data from the database, checking our invariants, inserting the changes back into the database, and dispatching an email.
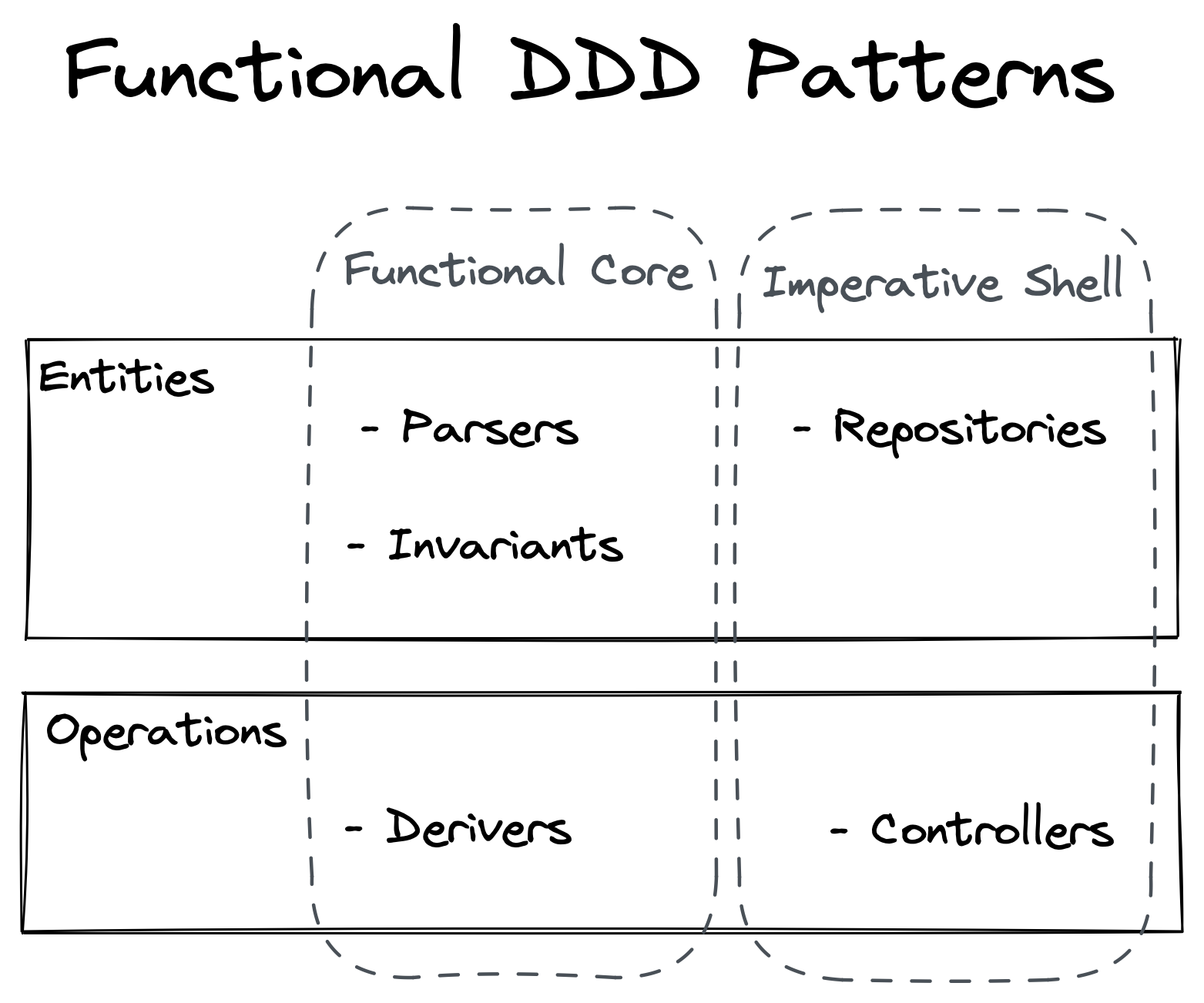
Let’s start from the top with our Functional implementation of entities, which lives across both Imperative Shell and Functional Core.
Entities
In fDDD, you will commonly implement Domain Entities as type definitions. For example, I might define a Policy in the Sales domain as follows:
type Policy = {
id: number;
customer: Customer;
salesPerson: Staff;
createdAt: Date;
}
While this approach to defining the entity is straightforward, it alludes to our implementation of various adaptors either in an anti-corruption layer or in our repositories, as we will cover soon.
A useful example might be our approach to parsing this entity when we receive it across the network. In that case, we may implement a parser function such as:
type PolicyParser = (rawData: unknown) => Policy | ParseError;
This parsing function would create a type-safe run-time implementation for bringing the Policy entity into our domain layer. Rather than implementing these parsers by hand, I often use a run-time typing package like zod.
Invariants: Functional Core
Invariants are Pure Functions with only one job: check that the provided entity meets a given business rule. In the case of an address entity, we might write an invariant that confirms that the provided phone number has an area code matching the address region.
export const validatePhoneMatchesCountry = (address: Address): boolean => {
if (address.phoneNumber ?? false) {
return false;
}
return getCountryFromAreacode(address.phoneNumber) === address.country;
}
As you can see, invariant functions can be tiny and very easy to test.
We primarily use Invariants by composing them inside Derivers. We may also, cautiously, create an invariant comprised of other Invariants if many Derivers share the exact composition of Invariants.
Derivers: Functional Core
Derivers are Pure Functions created to support a specific operation, such as createAddress or cancelSubscription. When we call a deriver, we must pass it all the information it requires to either derive the delta for our change or return an outcome indicating the cause for failure.
type UpgradeSubscriptionOutcome = UpgradeSucceeded
| AccountOverdrawn
| InvalidSubscriptionStatus;
export const deriveUpgradeSubscriptionOutcome = (
newPlanLevel: Subscription['planLevel'],
subscription: Subscription,
customer: Customer,
upgradePriceMap: PriceMap
): UpgradeSubscriptionOutcome => {
if (!validateCustomerBalance(customer)) {
return {
outcome: 'ACCOUNT_OVERDRAWN',
payload: { balanceOwing: customer.balance },
};
}
if (subscription.status !== 'ACTIVE') {
return {
outcome: 'INVALID_SUBSCRIPTION_STATUS',
payload: {
currentStatus: subscription.status,
expectedStatus: 'ACTIVE'
},
};
}
const prorataDays = calculateProrata(subscription);
const upgradeFee = upgradePriceMap[subscription.planLevel][newPlanLevel];
return {
outcome: 'SUCCEEDED',
payload: {
prorataDays,
upgradeFee,
},
};
}
In the Deriver above, we check two potential failure cases and then calculate the change required by the requested upgrade. Consider what we are not doing in this function:
Not getting the customer's details from the database
Not sending the customer a receipt via email
Not calling a payment provider to charge their credit card
Not saving the changes to the database
The core business rules for this operation have been condensed into a single function, enabling us to test every business rule. By keeping the scope of this function narrow, we can maintain its functional purity. This limited scope makes writing unit tests for this function less complex and makes the test itself more reliable. There are no opportunities for non-determinism, no database fixtures, and no stubs or mocks.
Controllers: Imperative Shell
We use Controllers to coordinate asynchronous parts of the system during an operation and call the Deriver. In the above example, the Controller would be responsible for each step we identified as out of scope for the Deriver.
export const upgradeSubscription = async (
customerId: Customer['id'],
newPlanLevel: Subscription['planLevel']
): Promise<UpgradeSubscriptionOutcome> => {
const [customer, subscription] = await Promise.all([
customerRepo.getById(customerId),
subscriptionRepo.getByCustomerId(customerId),
]);
const { outcome, payload } = deriveUpgradeSubscriptionOutcome(
newPlanLevel,
subscription,
customer,
UPGRADE_PRICE_MAP,
);
switch (outcome) {
case 'INVALID_SUBSCRIPTION_STATUS': {
return { outcome, payload };
}
case 'ACCOUNT_OVERDRAWN': {
await sendRepaymentReminder(customer, payload.balanceOwing);
return { outcome, payload };
}
case 'SUCCEEDED': {
const updatedSubscription = await subscriptionRepo.update({
...subscription,
prorataDays: payload.prorataDays,
planLevel: newPlanLevel,
});
const transactionId = await chargeCreditCard(customer.defaultCard);
await sendInvoice(
customer,
payload.upgradeFee,
updatedSubscription,
transactionId
);
return {
outcome,
payload: {
...payload,
transactionId,
}
}
}
default: {
isNever(outcome);
break;
}
}
}
As you can see in the above function, we are now dealing primarily with the asynchronous parts of the system. In these controller functions, we want as little business logic as possible. The example above is particularly complex; often, controllers only retrieve data from the database and save on success.
Notice, however, that the Controller does not make any business decisions. It only takes actions based on the result of the Deriver. It does not validate the subscriptions, and it does not check any rules.
However, the actions we take in certain circumstances, such as sending an email or charging a credit card, could be something we want to test. In that case, we can use the Partially Applied Controller pattern.
Testing via Partially Applied Controllers
If we want to make the previous example more testable, we can similarly use a partial function as we might use dependency injection in Object-Oriented programming. Let's take a look at an example:
export const createUpgradeSubscriptionController = (
customerRepo: CustomerRepository,
subscriptionRepo: SubscriptionRepository,
sendRepaymentReminder: (customer: Customer, balanceOwing: number) => Promise<void>,
chargeCreditCard: (card: CreditCard) => Promise<Transaction['id']>,
sendInvoice: InvoiceSender,
) => async (
customerId: Customer['id'],
newPlanLevel: Subscription['planLevel']
): Promise<UpgradeSubscriptionOutcome> => {
/* Remaining implementation is identical to the previous example */
};
// In an adjacent test file
const fakeSendRepaymentReminder = sinon.fake.resolves();
const fakeChargeCreditCard = sinon.fake.resolves('1a2bc');
const fakeSendInvoice = sinon.fake.resolves();
const upgradeSubscriptionTestController = createUpgradeSubscriptionController(
customerRepoInMemory,
subscriptionRepoInMemory,
fakeSendRepaymentReminder,
fakeChargeCreditCard,
fakeSendInvoice,
);
Now I can supply a test implementation of customerRepo & subscriptionRepo while also providing fakes for the other functions. Since this is a much more complex test, we don't want to repeat ourselves testing the Deriver's business rules. Instead, we only want to assert what functions the Controller calls for each of the Deriver's three possible scenarios.
Repositories: Imperative Shell
Repository patterns for retrieving entities on a CRUD basis are not solely a DDD pattern. Nor is it a significantly changed pattern between Functional and OO paradigms. For the sake of fDDD, I will only mention a few constraints to keep in mind for your repositories:
Keep database concerns constrained entirely to your repository layer
Parse, transform, or map all data types going into and out of your repository layer
A generic repository type could look like this:
type Repository<T> = {
getMatching: (query: Query<T>) => Promise<T[]>;
getById: (id: string) => Promise<T | undefined>;
create: (item: Omit<T, 'id'>) => Promise<T>;
update: (item: T) => Promise<T | undefined>;
upsert: (item: T) => Promise<T>;
delete: (id: string) => Promise<undefined | MissingEntityError>;
};
type Query<T> = {
[k: keyof T]: { operator: Operator, value: unknown },
}
Where the implementation of a create function may look like:
const subscriptionRepo: Repository<Subscription> = {
create: async (subscription) => {
const objKeys = Object.keys(subscription);
const result = await pool.query<T>(
`
INSERT INTO "subscriptions"
(`${objKeys.join(',')}`)
VALUES (`${objKeys.map((_, i) => `$${i+1}`).join(',')}`)
RETURNING *
`,
Object.values(subscription)
);
return result.rows.map(parseSubscriptionFromDb)[0];
},
// remaining repo functions omitted
};
In the above example, our repository maps from the database type back to the domain entity types using the parseSubscriptionFromDb function. This mapping helps us maintain a layer of separation between the database and our implementation. It also allows us to narrow the types further while throwing errors if the database returns unexpected data.
Software Architectural Context
Now that we have defined the patterns of our fDDD implementation, we need to consider its place in our overall software architecture. If we were to implement fDDD in a typical Express.js application, we could implement it as follows:
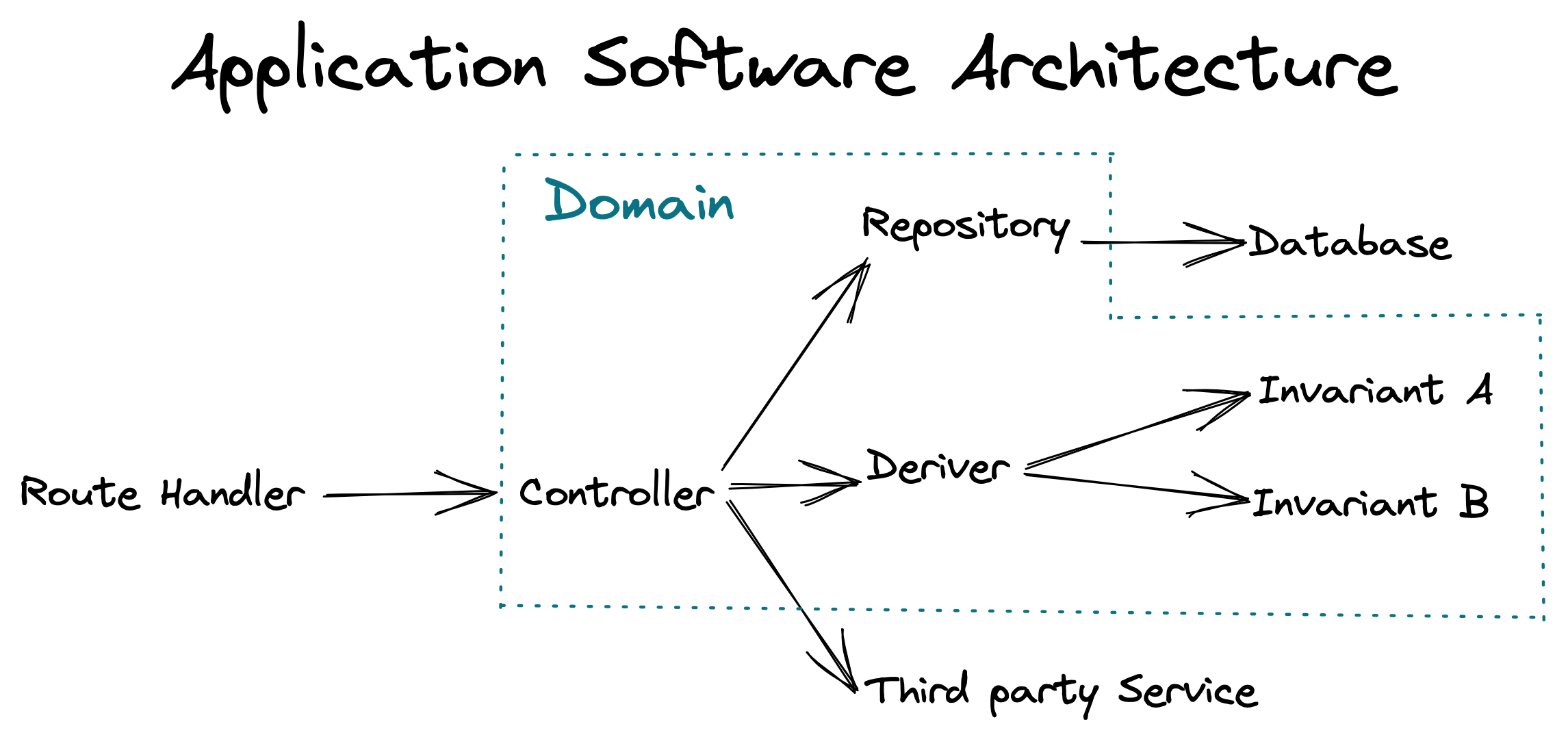
Our Route Handler for a POST request to /api/subscriptions may look like this:
export const handleSubscriptionPost: RequestHandler = async (req, res) => {
const customerId = req.jwt.customerId;
const { subscriptionLevel, paymentToken } = req.body;
const { outcome, payload } = await createSubscription(
customerId,
subscriptionLevel,
paymentToken
);
switch (outcome) {
case 'PAYMENT_FAILED': {
res.status(400);
break;
}
case 'SUCCEEDED': {
res.status(201);
break;
}
}
res.json({ outcome, payload });
};
All our route handler is responsible for is:
Preparing data from HTTP requests for consumption by the Controller
Mapping outcomes back to HTTP status codes
The route handler has no opinions on the business rules, and the domain code has no knowledge of content types or status codes.
When it comes to planning the structure of our codebase, there are primarily two dimensions we could choose as the basis for our files and folders:
Application layers, e.g. database, route handlers, domain, services
Operations, e.g.
createSubscription,updateUser, etc
The former has the advantage that all of the code for a particular area is easy to find, but the trade-off is that implementing a change requires opening many folders. The latter has the advantage that all related code for any given change is likely to be nearby, but it is harder to find other code that may operate similarly or be affected by your change.
When we structure our codebase for a Domain Service, our preference is to keep all of the domain code as closely co-located as possible.
This preference means our top-level folder structure will be along the lines of:
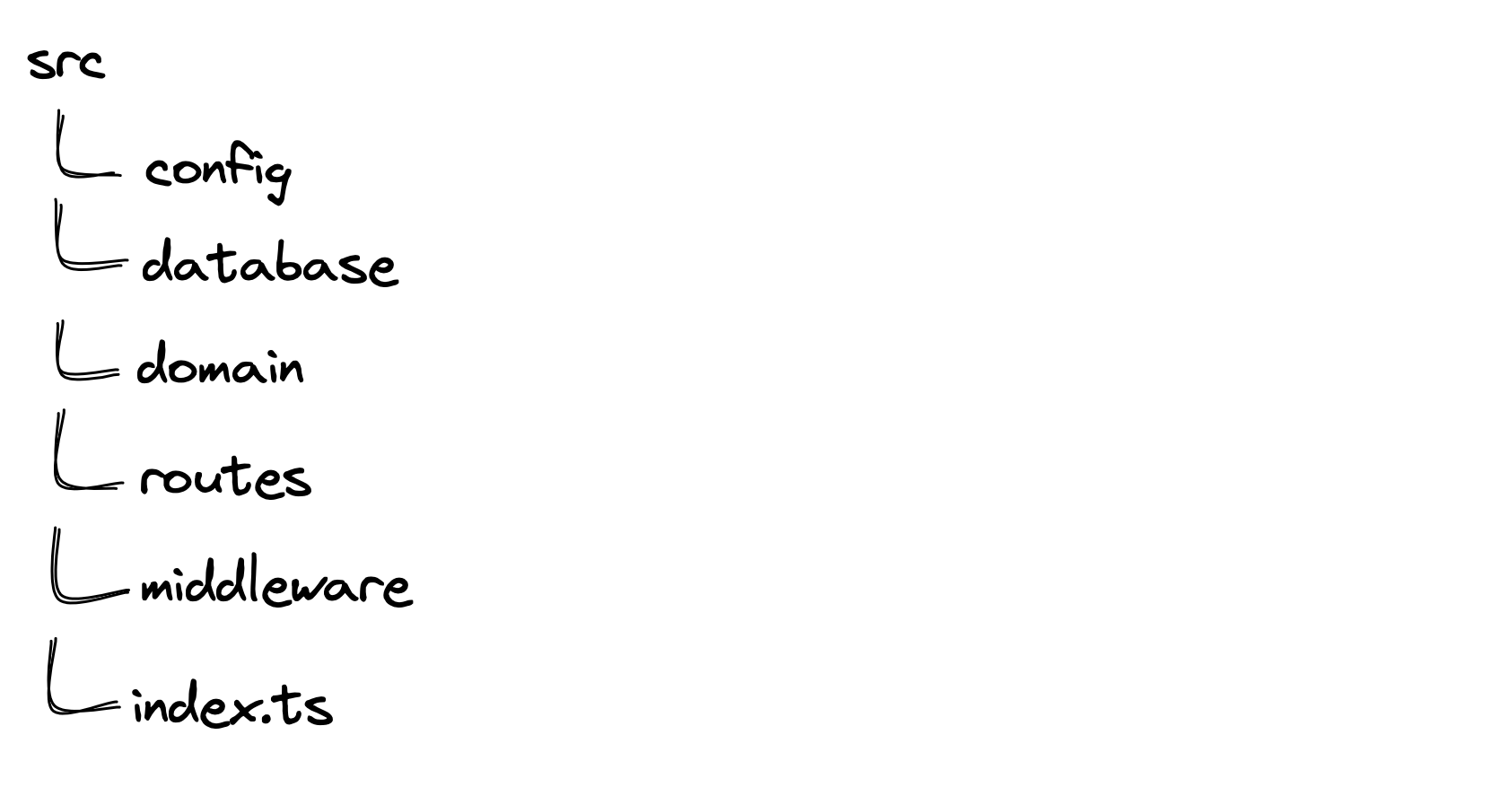
However, we will then split it into "entities" and "operations" sub-folders inside the domain folder.

This structure increases the likelihood of reusing an entity's invariants in different Derivers for each operation.
Wrapping Up
Hopefully, this article has shown you how to implement Domain Driven Design within a Functional Programming paradigm and successfully make complex software more manageable. As you can see, fDDD simplifies many of the complicating factors in a classical DDD implementation. Here's a quick refresher on what we have learned:
Entities are at minimum a type definition and may include a parser for run-time validation
Invariants take an Entity as an input parameter, validate it against a simple business rule, and return a boolean
Derivers take one or more Entities as an input parameter, validate it against operation-specific business rules, compose related Invariants, and return a discriminated union of potential outcomes
Controllers coordinate asynchronous parts of the system, including databases, on behalf of Derivers
The wider application accesses the Domain Layer strictly via Controllers


