
Your Microservices Are Slowing You Down, could Domain Services Boost Productivity?

The benefits of a Microservices Architecture are well known; they reduce coupling, allow independent deployments, and increase the rate of change in our applications, making product managers love us, finance teams applaud us, and CEOs offer us big bonuses. Or so I keep being told at conferences.
However the costs of a Microservices Architecture are not talked about nearly as often as they should be. The trade off when we create a new Microservice is increased technical complexity, increased coupling, dependent deployments, greater risk of introducing distributed transactions, and overall a decreased rate of change in our applications.
Wait a minute! The costs sound almost identical to the benefits, so what's going on here? Some of the dogmatic enthusiasm for Microservices is due to our familiar old friend the causal fallacy. Microservices architectures correlate with other beneficial behaviours, up to a point, beyond which their costs exceed their benefits and the approach begins providing negative value.
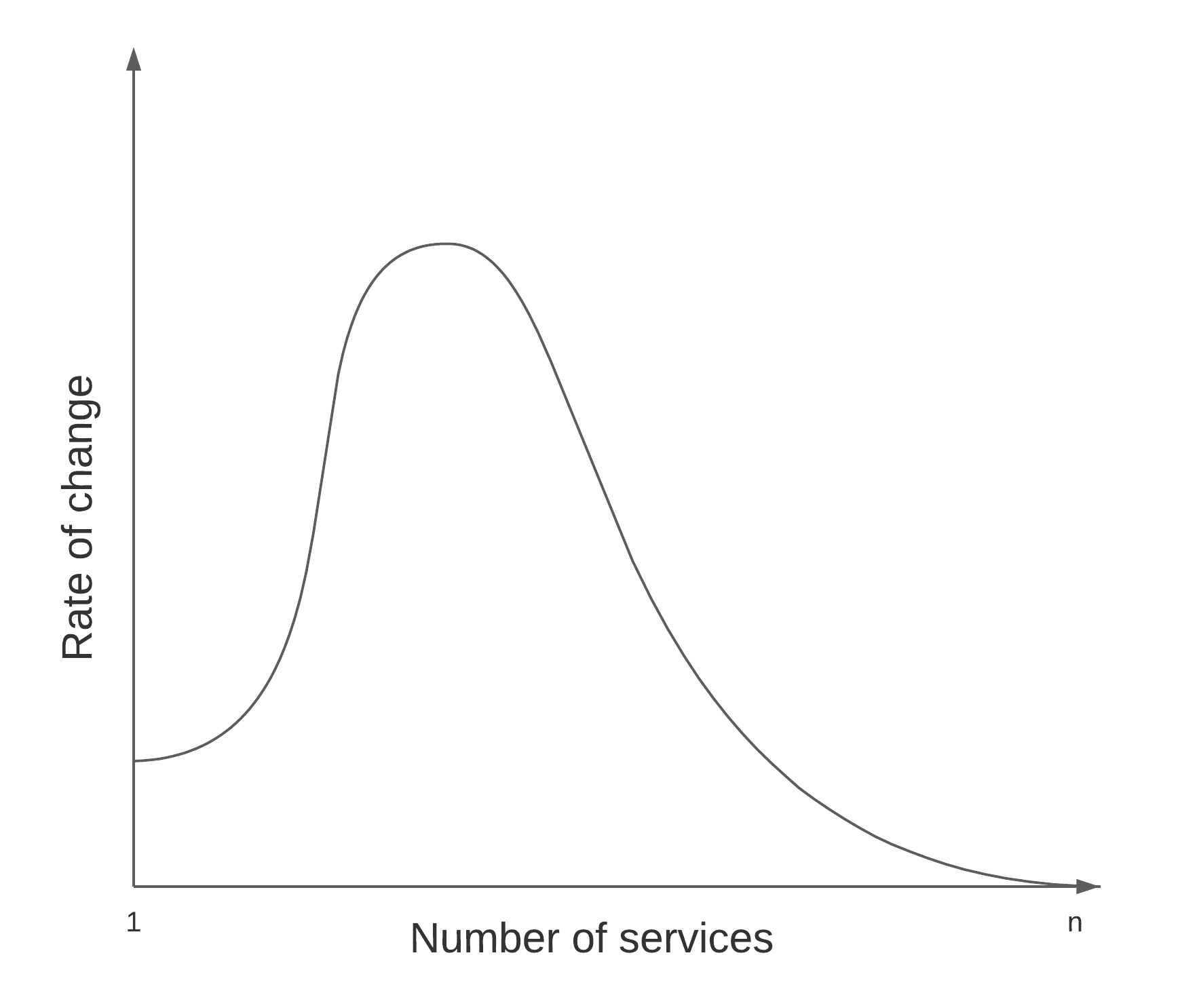
This benefit is non-linear, the first few Microservices provide a lot of extra value! But these returns quickly diminish, until the Microservices architecture itself becomes a hindrance, in some instances reducing productivity to the point where change is now harder than it was before.
The irony of the negative value phase is that the system has created a feedback loop where the cost to create a new Microservice is low, and the pain is distributed across teams/engineers in the organisation. No one can solve the problem individually, everyone must agree, but whoever continues creating new Microservices reaps the benefits of another team's good behaviour. Microservices architecture can thereby create a system implementing tragedy of the commons. This is how companies wind up with thousands of Microservices, even after the approach shows its flaws.
My goal in this article is not to persuade people that Microservices Architecture is bad. Instead, I want to expose the root cause behind the initial rise in productivity with Microservices, and then find ways to maintain or extend it. My objective is to create an approach that helps us find and stay at the top of the hill where we have the greatest rate of change. I want to give us a set of tools to know when to apply this architectural approach, and how far to go.
The reason Microservices work so well at first is because, when you break up your system into tiny components, it is highly improbable that a single new service with a single responsibility will cross domain boundaries. Your first Microservice was a success, so you build a few more. Along the way you re-allocate these services between teams quite easily as you intuit where the domain boundaries are in your business. So far so good, and quickly you build up tens, then hundreds, and maybe eventually thousands of Microservices, as Uber did.
This is what I call the shotgun approach to Microservices architecture, and it usually occurs due to a lack of design. If you make the pieces small enough, no one has to do the hard design work of identifying bounded contexts or designing domains up front. Instead you can always trade service ownership between teams. The person who championed the approach in the beginning gets lots of praise as the team climbs the hill in the above diagram.
And then the wheels fall off. The top of the hill is a narrow precipice.
Probably around the time you (accidentally) create your first distributed transaction, you realise your Microservices aren't so decoupled, and perhaps you have built a distributed monolith. Every feature that made them great before, now makes them challenging. If you make a change to a service, you can't reasonably tell which other services are directly or indirectly affected. Observability becomes a nightmare, where a single user interaction may be handled by a dizzying number of services talking to each other. What was once function calls in code has now become distributed network requests that must be traced. An outage in one service results in a set of failures that light up your alerting systems like a Christmas tree, making the root cause a nightmare to diagnose.
Whole new solutions are invented to solve problems that teams created for themselves, further increasing complexity and the likelihood of unpredictable emergent behaviour creating incidents of change failure, which themselves become increasingly difficult to solve.
You might be building and deploying small Microservices independently, but the meaningful non-functional requirements live at the system level. You can't reasonably test the suitability of a Microservice deployment in isolation, because the system behaviour is contingent on the whole. As we reduced the responsibilities of a service down to a single purpose, we too reduced it's overall contribution to the -ilities that make our system manageable.
Likewise, Microservices may be deployed independently, but meaningful, value-adding change that the business asks for requires changes to multiple Microservices. With too many services, these changes themselves cascade across services. You've gone from one deployment containing many changes, to one change requiring many deployments.
What's the alternative? Like abstract versus concrete classes, decoupling vs cohesion, the answer is applying things appropriately, and moderately. The key benefit of the first few Microservices is that we create an architecture where teams are empowered to deploy code changes that align with the axis of change in the business. So how do we define moderate and appropriate?
Typically, the first system we split out is one that is obviously discrete, such authentication or payments. The boundary between the new service and the old service is easy to identify: a small surface area of interaction, either side of which the two services are relatively independent. It's easy to get right, hard to get wrong the first time. But taking this first win and going from a crawl to a sprint is ill advised.
Instead, take the time to do planning and analysis before creating your Microservices. This planning typically has to occur sometime after the business has actually begun operating. Planning a Microservices architecture in a greenfield product before achieving product market fit is a sure way to get the bounded context wrong. You're aiming for a fast moving target. During the incubation phase, there's more to be gained by focusing on building differentiators and buying the rest than there is in architecting Microservices.
However with a product in the growth or extraction phase, you can analyse existing code in a well architected monolith, and don't split your services if you can't create a well architected monolith first. Look for clear business domains with very few dependencies on other parts of the code. These are vertical slices of the code you are likely to be asked to change by a product manager, and would be relatively easy to do so in one atomic change.
One technique is to go through Jira comparing past tickets to the code base. The crucial factor here is to align your domains along the axis of change, and our ticketing system is a great way to identify what tends to change discretely and what changes dependently.
You see, the rate of change is determined by the number of dependencies affected by that change. This is true in terms of code AND organisation; that is, your team structure should reflect your business domains which should reflect your code and your architecture. The more these four elements align, the lower the resistance and the faster the rate of change.
The perfect example of this is simply aligning services or teams along the wrong axis. That is, if you have a frontend Microservice, an API gateway Microservice, a few business logic services, and something crazy like a database service. Then imagine that each service had its own team. In this (slightly) contrived example, we have built teams and services around the layers of our application, rather than vertical slices. Since no change can occur without affecting all layers, teams AND services have to communicate a lot in order to deliver change or value.
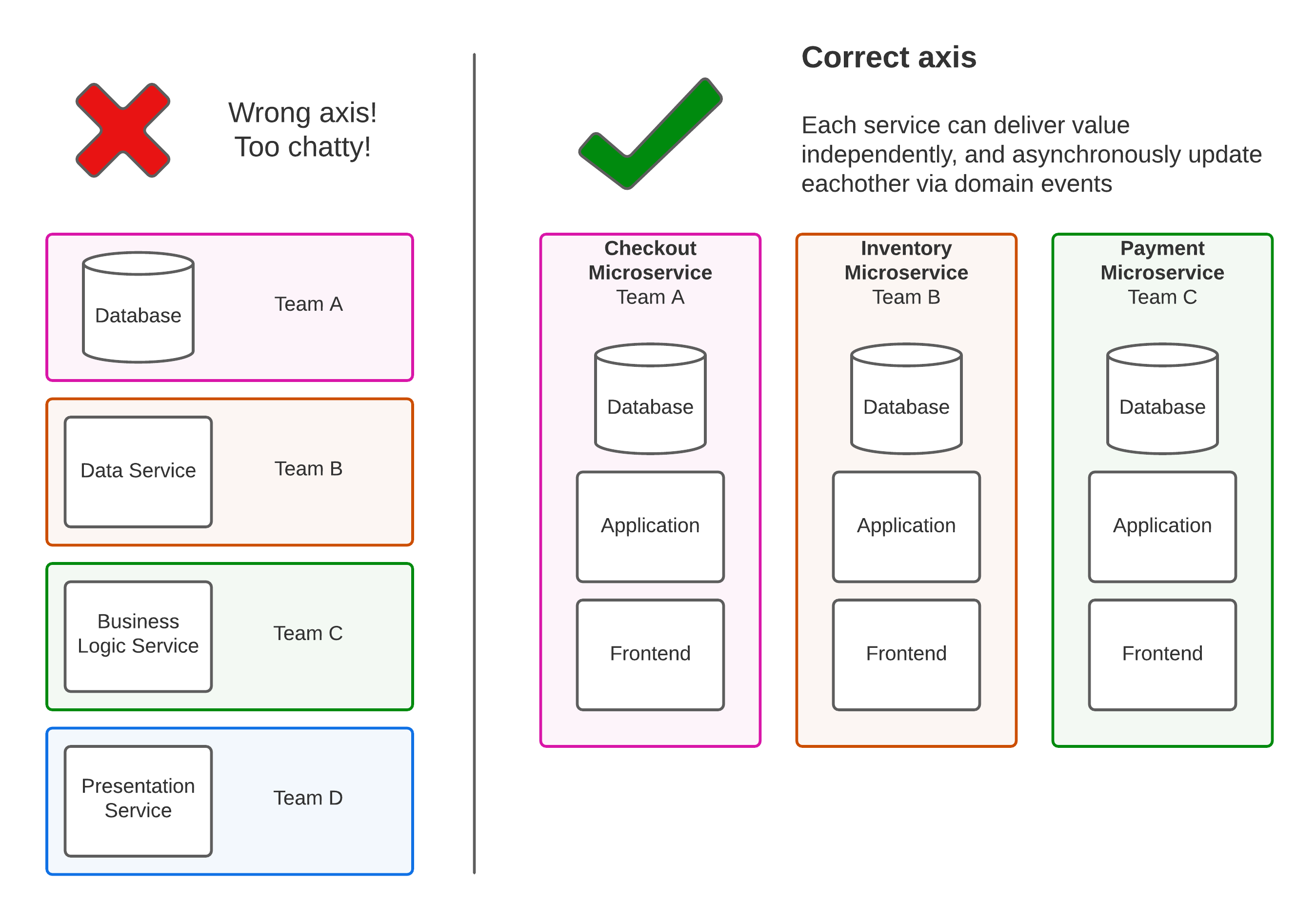
A Microservices Architecture may start out looking like the diagram on the right, but if you're not careful, the quest for smaller and smaller services will inadvertently lead teams to create something akin to the diagram on the left. Remember, you're optimising for changeability, not reusability. They are two competing goals!
What you ultimately want to do is apply Domain Driven Design to find a small number of discrete, well bounded domains. Then you can structure your teams, code, architecture, and business around these domains.
I believe that finding the correct name for this approach and its services is crucial. The term Microservices seems to imply that more and smaller is better. However as we have seen, discrete and well bounded is far more important than size or number. That is why I have chosen to call them Domain Services*. This name reveals our true objective; aligning teams, code, and architecture with business domains.
My rule of thumb is that the number of Domain Services an engineering department should aim for is the number of feature engineers divided by three or five. That means a team of 10 engineers developing features should have 2 or 3 Domain Services, not 20! A team of 30 feature engineers could have 6 to 10 Domain Services.
This ensures that the services are large enough that they are easy to maintain transaction boundaries within them. The number of discrete domain boundaries that you have to find is reduced, and teams only have to create and maintain a contract/context map for the entities that are communicated across that exposed boundary, keeping communication costs low while greatly enhancing rate of change.
You may have heard that "Microservices should do only one thing!" but I would argue that this only seems true because it implicitly enforces the more accurate rule:
A domain must only be implemented in one service, but a service may implement more than one domain
This matches its sister rule in Domain Driven Design:
A domain must only be worked on by one team, but a team may work on more than one domain
Each Domain Service you add should be planned and executed with extreme caution! Every time you add a service, you increase the number of exposed domain boundaries rapidly. An exposed boundary is a domain boundary that is implemented across the network, between services. Every exposed boundary introduces an API surface that enforces a contract. A contract must be maintained or versioned through changes.
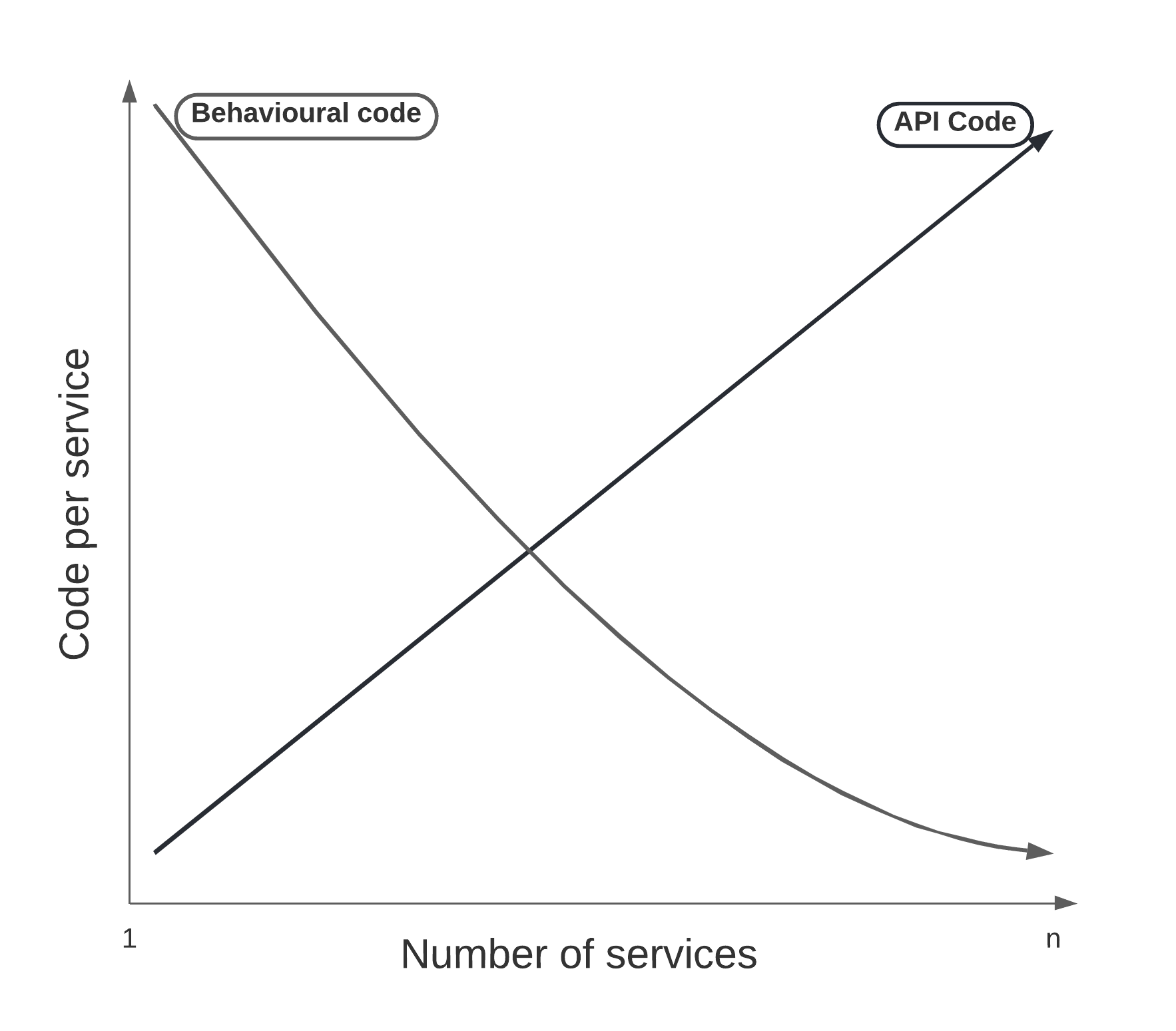
The more boundary exposure you have, the slower your rate of change behind that boundary. Heuristically speaking this means that if your service is too small, the ratio of behavioural code and API code tilts toward API code. As it does the utility of the service approaches zero, since any change in behaviour will more likely result in a change in API. The more Microservices you have, the smaller their behavioural code, and the greater their boundary exposure, soon every Microservice is more API than behaviour and productivity halts.
The reason we began creating Microservices in the first place was to increase the rate of change in behavioural code — a benefit we lose as we add more services. The business doesn't ask us to change API code, the business asks us to change the behaviour of the system. The API is meant to help facilitate that change, not hinder it.
For example, two Domain Services can have only one boundary and zero possible dependent services, three services gives us three boundaries, four services gives us up to six, and so on. This is without considering indirect dependencies, which can accumulate even faster.
| Services | Boundaries | Indirect Dependencies |
| 2 | 1 | 0 |
| 3 | 3 | 3 |
| 4 | 6 | 12 |
| 5 | 10 | 30 |
The indirect dependencies column describes how a command from one service to another could subsequently depend on the remaining services. That is, if we have 4 services, for each service one of those services could issue commands to, each of those could depend on the two remaining services. When all of those possible dependencies are accounted for at a single depth, we have 12 opportunities for dependent calls.
Of course, these numbers represent the upper bound, the worst case scenario. Importantly they show how too many Microservices quickly turns into a new big ball of mud — the very thing we wanted to avoid, just with added network, concurrency, and deployment issues.
As you can see from the above table, the change from two Domain Services to three is almost as important as the change from one to two because a third service introduces new types of complexity. You will likely be carving this new Domain Service out of an existing one, so you must be thorough. Check that the candidate Domain Service doesn't cross transaction boundaries, investigate all the events and commands within the domain, and work with your product manager and/or business analysts to ensure your model of the domain matches theirs.
Modelling domains as a collection of commands, events, and aggregates, entities, or projections helps a lot with this process. Even if the code here is well established, it can be worth running an event storming session.
At this point in the article it is worth running through a definition of commands and events, because understanding the distinction between the two is critical. The simplest definition I have come up with is this one:
A command is a request to change the persisted state; An event is the delta of that change.
That is, every time you would write to a database, whether that is an insert, update, or delete, emit an event which describes what changed (NOT the new state!) An event cannot be rejected because it is a historical statement of fact. It might not be a happy fact, but it is one nonetheless.
Every time you have the intent of changing state, issue a command, knowing that it could be rejected. Commands can have outcomes, which might be the reason the command was rejected, or it might be acknowledgement that the command was accepted. When a command is accepted, an event must eventually follow.
It's important to note that events are the transaction boundary. In an event based system with multiple services, your system has to be and expect eventual consistency.
Let's say your checkout service issues a CompletePurchase command, and checks its simplified inventory data before accepting the command. It then emits a PurchaseCompleted event to the inventory service,which has a much more sophisticated understanding of inventory. At the same time, the inventory service has sent a StockAdjusted event because someone has reported an item as damaged at the warehouse. The inventory service now realises that it can't service the order because the available stock is no longer available. Should it reject the PurchaseCompleted event?
No. The purchase happened, the user's credit card has been charged. This is a matter of historical fact and cannot be rejected. You might say we should have prevented the purchase then, "if only we had kept these domains together!" you lament. But remember, the inventory domain only updated its available inventory count after the damage physically occurred in the warehouse. The real world itself is eventually consistent anyway!
In this example, you can see that the domain events are the true transaction boundary. A PurchaseCompleted event might lead to an ItemAllocated event from the inventory domain in the green path, reducing the available stock count, but the fact that these two events are correlated does not make them an atomic action.
If you model your domains this way, you will find that the domain boundaries are quite clear, and that the events and commands that are shared between them define the API boundaries between our Domain Services.
The reason this distinction between commands and events is crucial is because it relates to another key rule of Domain Services:
Communication between Domain Services should consist of events, not commands
If your Domain Services are issuing lots of commands to each other, this is an indication that your domain boundary is incorrectly placed. A single user interaction should result in a command within a single Domain Service. The primary Domain Service handling the initial command may dispatch one or more events to other Domain Services, which may themselves issue commands to themselves on receipt of the event (but not when replaying the event from their own event store). However these must be events, not commands, and must fail independently.
The result is that a user interaction may be satisfied by a single Domain Service without issuing dependent commands. This does not however, preclude additional responses from the events occurring asynchronously. E.g. if the Checkout Service emits a PurchaseCompleted event then the Notification Service may email the user an invoice based on the event it received and their preferences it has stored. The Dispatch Service may issue a CreateFulfilmentOrder command and begin the process of shipping goods to the user. Each of these commands may fail, but they fail independently.
Let's compare this to a shotgun Microservices Architecture implementation. In the shotgun approach, the CompletePurchase "command" may be a call to a Microservice that validates the cart, which then calls another service to check the billing, while also calling another service to reduce the stock levels, and another to create a carrier label for shipping, another service to update the users order history, and another service to email the invoice. All of these calls may be commands to other services, and all of them may fail in dependent ways which are then (hopefully) fed back to the user.
Coming back to the crux of this article, I am confident that a team of 35 developers working across 7 Domain Services will in the majority of cases, outperform a team of 35 developers working across 60 Microservices. Of course, no quantitative measure exists, but the stories of development teams reducing and reorganising their Microservices provides qualitative evidence to support my hypothesis, in addition to my personal experience, and deductive reasoning outlined in this article.
Ultimately the goal of any architecture is to facilitate ease of change into the future, without sacrificing our target non-functional requirements. This architectural objective is predicated on our ability to predict the nature of changes into the future. Of course, all predictions are imperfect, and increasingly so the further our outlook. However I believe Domain Services better aligns our architecture with our team structure and business structure by utilising tools such as Domain Driven Design to identify numerous independent (or at least loosely coupled) axes of change in our systems.
Summary of Heuristics and Rules
We covered a lot of ideas in this article, so we will quickly recap the key thoughts. I have split these into heuristics and laws.
The heuristics are rules of thumb that are usually true in any software system with "services", whether that is Microservices or Domain Services. I find these are useful ideas to keep in mind when consider the trade offs of introducing new services.
The laws are rules that define best practices for a Domain Services approach, and thus uses the language of RFC 2119
Heuristic of Multi-Service Systems
- As new services are added, complexity increases non-linearly
- As new services are added, rate of change increases by at most +1
- The total rate of change increases as the deployment to change ratio approaches 1:1
- The rate of change is reduced by the number of dependent/affected systems/teams for each change
- The utility of a service is its amount of behavioural code compared to API code
- Increasing the number of services reduces the amount of behavioural code in each service
- Increasing the number of services increases the amount of API code in each service
The Laws of Domain Services
- A domain must only be implemented in one Domain Service, but a Domain Service may implement more than one domain
- A domain must be owned by only one team, but one team may own more than one domain
- Domain Services must only communicate asynchronously
- Domain Services must communicate via events
- Domain Services should not dispatch commands to other services
- Events must be an atomic transactional boundary
- Events must never be rejected (but they can be ignored)
- Commands must be a rejectable request to change the persisted state
- Events must be a semantic encapsulation of the delta of altered state, and an immutable historical fact
- An accepted command must produce an event
- A Domain Service may issue a command to itself when it ingests an event from another Domain Service
- Domain Services must not share persistence layers
- A Domain Service should only receive data it requires from other Domain Services via events
- A Domain Service should not request additional data from another Domain Service in order to handle a command
Footnotes
* Fans of Domain Driven Design, especially those whom follow the Object Orientated implementation, might recognise the term as an implementation level pattern in code. Given the term isn't referenced in DDD: Distilled, seems to cause confusion, and isn't well distinguished from other DDD patterns, I feel that we can make better use of this term at the architecture level. Therefore I have stolen and repurposed it, sorry not sorry.


