
Applying Google's Testing Methodology to Functional Domain-Driven Design For Scalable Testing

Recently I wrote an article about applying Functional Programming to Domain-Driven Design. One of the key benefits of that approach is improved testability, but we didn't get to delve into it too deeply.
In this article, we will consider what factors make an automated test suite great. We will bring together a lot of ideas from Software Engineering at Google. Whenever I refer to "Google" in this article, I am referring to the authors' depiction of Google's engineering practices in the book.
I will also translate some of Google's testing methodology to TypeScript. We will then see how it fits with Functional Domain-Driven Design (fDDD).
Good Test, Bad Test
Let's start by defining what a good or bad test suite is.
There are five dimensions we can use to consider the quality of our tests. These are brittleness, flakiness, speed, and readability. In the same sense that optimising outside the bottleneck is wasteful, the metric a team needs to focus on improving is whichever one is worst at any given time.
Brittleness (Durability)
A test is considered brittle when it breaks due to unrelated changes. If you have ever changed a small piece of code as part of a (supposedly) simple ticket and wound up failing scores of seemingly unrelated test cases, you have experienced the frustration of brittle tests.
Good tests should be updated less frequently, while bad tests sap productivity with needless changes. Measuring how often tests are changed can be an effective way of finding brittle tests.
Flakiness (Reliability)
A flaky test is a non-deterministic test. That is to say; sometimes it fails despite neither the code nor the test changing. When tests are flaky, our continuous integration and deployment pipelines suffer from unnecessary re-runs, our lead time for changes grows unnecessarily, and worst of all, engineers pay less attention to the tests.
We can measure flakiness in the number of times we can run a test suite and have it return the same result. That is to say that a test suite that, if I ran it twice, failed once and succeeded once, its flakiness would be 100%. The equation for flakiness percentage is failures / successes
Speed
Tests work best when they can provide real-time feedback as part of an engineer's workflow; The best tests can run in the IDE while the engineer is coding. However, as we will see later, some tests must sacrifice speed to interrogate the subject under test.
Fast tests improve the local development experience, increase the utilisation of tests amongst engineering teams, and improve the lead time to deployment.
Readability
Ultimately our tests need to document expected behaviour for other engineers to read. Since the best tests are updated the least, they will likely be read many more times than they are written. The best tests are clear, concise, and simple. Each test should only test one behaviour. The prerequisites, action, and expected result should be clearly expressed such that even someone unfamiliar with the code can understand the test.
A good litmus test for test cases can be checking if a non-technical stakeholder such as the Product Manager understands them.
Accuracy
It's great having durable, reliable, fast, and readable tests, but it is all for naught if the tests continue passing when the system's behaviour changes in a breaking way. However, accuracy doesn't become a focus for many teams because they struggle with the other dimensions of testing. Most teams only write example-based tests, which have the least accuracy, but other methods such as property-based testing and mutation testing can help ensure that our tests are rigorous and improve their accuracy.
Big Test, Little Test
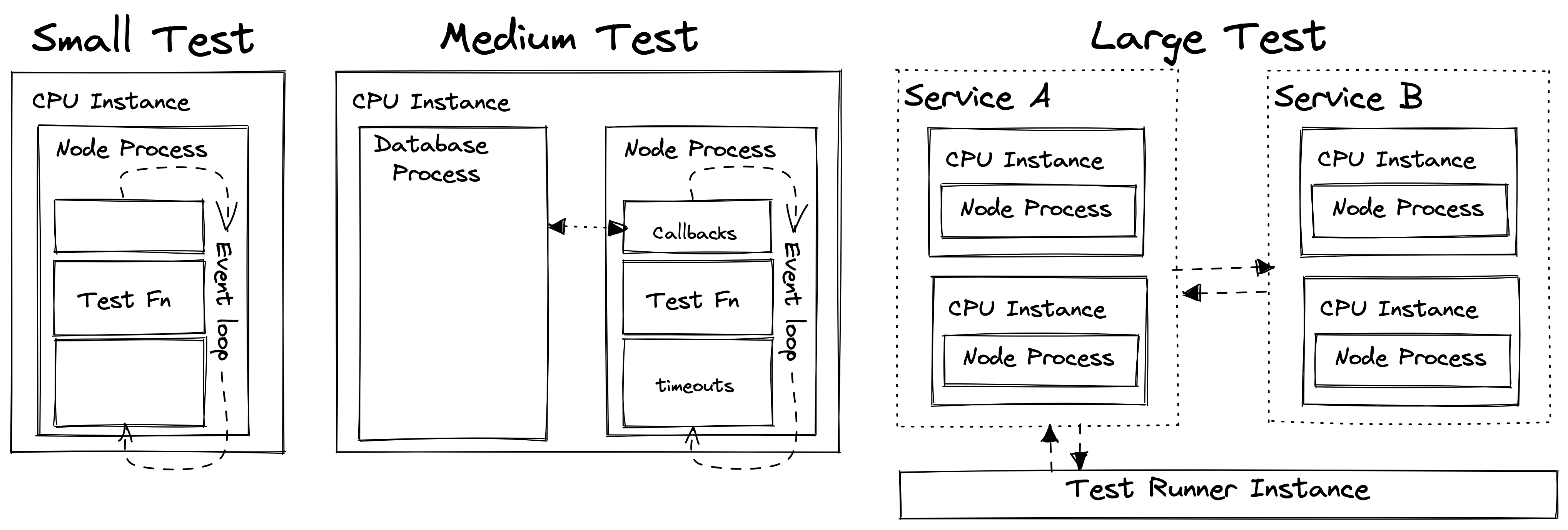
While most people consider tests in terms of unit, integration, and end-to-end tests, Google has a more precise hierarchy of tests: Small, medium, and large. But what do these classifications mean? They might sound subjective, but they each have a specific objective definition.
Small Tests
Google's rules for small tests are:
- The test must run on one thread on one machine
- The test must not use sleep
- The test cannot perform I/O
- The test cannot make blocking/async calls
In TypeScript, these translate to:
- The test must run in one Node process
- The test must run synchronously: it cannot use async/await/promises
- It must run in a single tick of the event loop (this means no using setTimeout or setInterval for side-effects)
- The test cannot perform I/O (it cannot use synchronous file-system access, for example)
I would also add two more constraints:
- The test must not utilise system time
- The test must not utilise pseudo-random number generators or randomness of any kind
In practical terms, this rules out testing against a database, mocking asynchronous systems (a cause of much brittleness AND inaccuracy), and even starting an Express server in the test suite.
Medium Tests
Google's rules for medium tests are:
- The test may run on multiple threads or processes, but only on one machine
- The test may make blocking calls
- The test may call localhost, but not the network
In TypeScript, these translate to:
- The test may run an additional node process, may utilise a local database, etc
- The test may use async/await (Promises)
- The test may use multiple ticks of the event loop
- The test may perform I/O
- The test may call localhost, but not the network
In practical terms, you can now test against a local database, use a tool such as Supertest to test your Express server, and more.
Large Tests
For large tests, all the constraints are removed. An example of a large test would be using Cypress to run end-to-end tests against a staging deployment. As we know, networks are both laggy and unreliable, so these tests have the highest flakiness and slowness.
Comparing Test Sizes
With these constraints in mind, we can see that small tests are the best performing in all categories:
- Durability: Small tests necessitate a limited scope, so it will be less likely that they will inadvertently rely on related components
- Reliability: The constraints for small tests remove all opportunities for non-determinism to enter the test suite
- Speed: Small tests are CPU bound, consume the least resources and are therefore faster than their larger counterparts
- Readability: Small tests are generally simpler and thus easier to understand
- Accuracy: While small tests are not intrinsically more accurate on their own, their other attributes make it easier for engineers to write and run more of them, more examples, and even use approaches such as property-based testing.
For this reason, we strive to define our test pyramid, not in terms of unit or integration tests, but instead based on this size taxonomy:

As we move further up the pyramid, we lose out on all five factors of a good test. For this reason, we want to structure our code such that this distribution of test sizes is feasible. This code structure is where fDDD can help us!
Testing in Functional DDD
Writing Small tests can be highly challenging unless we take care to structure our code in specific ways. Luckily Functional DDD gives us precisely this structure. From here, I will continue assuming you are familiar with fDDD.
Small Tests: Derivers & Invariants
Since both Derivers and Invariants are Pure Functions, their tests automatically meet the criteria for smallness. This functional purity allows us to test our most valuable code quickly, easily, and to a high standard.
Medium Tests: Controllers
Controllers break the synchrony constraint and so cannot be deemed small tests. However, we can still benefit significantly by using the Partially Applied Controller pattern to reduce dependencies such as a local database, remove network requests, etc. We should strive to make even medium-sized tests as small as possible!
Another way of improving the balance between small and medium-sized tests is to remove tests for Controllers where they provide little value. Testing a Controller that simply flushes the derived result to the database on success is not a very valuable test.
If the test provides almost no value, then it may have a net-negative impact due to the increased brittleness and flakiness it could introduce. Having a solid foundation of small tests makes it easier to remove low-value medium-sized tests.
Large Tests
Large tests are not a concern of fDDD, but we will mention them for completeness. Large tests are most useful for testing configuration, emergent behaviour, and evolutionary architecture against fitness functions.
Types of large tests include:
- Automated UI tests on deployed applications
- Automated API tests on deployed applications
- Load testing on deployed applications
- Performance testing on deployed applications
The critical distinction here is that we are testing the entire system in the context of a deployed application. We could implement UI, API, visual regression, and performance testing as medium-sized tests, which would make them easy to run on pull-request, but they wouldn't be testing the system.
However, large tests are expensive, and most teams need to prioritise which non-functional requirements are critical to their applications.
Improving Readability
This article has spoken about flakiness, brittleness, accuracy, and speed, but we haven't talked much about readability yet. Let's discuss a few simple ways we can improve the readability of our tests.
Hermeticity
A test should contain everything it needs for setup and teardown while making no assumptions about the external environment, such as the state of the database.
For example, we once had a flaky test suite that was hard to track down. It was slightly more reliable in CI, but it was extremely flaky on local. It turned out that there were two pieces of code referencing a feature toggle in the database. One of these tests would change the state of the toggle, so the order that the tests were executed in could change the outcome of the test suite! But worse than that, people's local databases often weren't in a state compatible with the test.
In this case, the test's readability was poor because we defined part of the test's behaviour in an entirely separate system. A system that the test code didn't reference.
No logic
Tests should be so simple that they must not use control-flow statements such as if, for, and while. If your test is so complex it could have its own test, it isn't going to be effective, and it certainly isn't going to be clear to another developer when their change breaks your test.
Behaviour-based tests
Each individual test case must test one and only one behaviour. This rule is made clearest with an example:
it('updateUser', () => {
const user: User = { email: 'foo@bar.com' };
const result1 = updateUser(user, { name: 'bronson' });
expect(result1).to.deep.eq({ email: 'foo@bar.com', name: 'bronson' });
const result2 = updateUser(user, { email: 'bar@foo' });
expect(result2).to.deep.eq({ error: 'invalid email address' });
});
The test above is trying to test an entire function, rather than a single behaviour of that function. We can improve the clarity of this test by splitting it into two behaviour based tests:
describe('updateUser', () => {
it('should add a name property to an existing user', () => {
const user: User = { email: 'foo@bar.com' };
const result = updateUser(user, { name: 'bronson' });
expect(result).to.deep.eq({ email: 'foo@bar.com', name: 'bronson' });
});
it('should return an error when supplied an invalid email address', () => {
const user: User = { email: 'foo@bar.com' };
const result = updateUser(user, { email: 'bar@foo' });
expect(result).to.deep.eq({ error: 'invalid email address' });
});
});
Now if I accidentally break the email validation logic, the test failure cause will be apparent even before I read the test code.
DAMP, not DRY
Google defines DAMP as promoting "Descriptive And Meaningful Phrases" -- a reverse-engineered acronym if I ever saw one. However, the principle is sound; tests benefit more from clarity than code reuse.
In the following example, we have created helper functions to setup test state:
it('should allow users to send friend request', () => {
const users = createTestUsers(2);
const { outcome } = sendFriendRequest({ from: users[0], to: users[1] });
expect(outcome).to.eq('SUCCESS');
});
it('should not allow a banned user to send friend request', () => {
const users = createTestUsers(2, true);
const { outcome } = sendFriendRequest({ from: users[0], to: users[1] });
expect(outcome).to.eq('BANNED_USER_CANNOT_SEND_REQUEST');
// This test suite is failing
});
And then elsewhere in the file:
const createTestUsers = (numUsers: number, ...bannedUsers: boolean[]): User[] => {
const users = Array.from({ length: numUsers }, (_, idx) => ({
email: `user${idx+1}@test.co`,
banned: bannedUsers[idx+1] ?? false,
});
return users;
};
The issue is that while reading the test cases, it is unclear what is happening, and is actually dependent on iteration logic inside the helper. Did you spot the bug? Consider instead:
it('should allow users to send friend request', () => {
const user1: User = { email: 'user1@test.co' };
const user2: User = { email: 'user2@test.co' };
const { outcome } = sendFriendRequest({ from: user1, to: user2 });
expect(outcome).to.eq('SUCCESS');
});
it('should not allow a banned user to send friend request', () => {
const user1: User = { email: 'user1@test.co', banned: true };
const user2: User = { email: 'user2@test.co' };
const { outcome } = sendFriendRequest({ from: user1, to: user2 });
expect(outcome).to.eq('BANNED_USER_CANNOT_SEND_REQUEST');
});
Here the difference between test cases has been made explicit within the test cases themselves.
Conclusion
Now that we've defined the five factors of a good test suite, Google's test size taxonomy, the benefits of fDDD in test quality, and a few tips for improving test readability, hopefully, you have a few ideas for improving your team's automated testing. Of course, there is a lot more that one could say about writing great tests, but I will leave that for another article.
Summary:
- You can measure the quality of a test suite in terms of brittleness, flakiness, speed, accuracy, and readability
- Google break their tests down by a taxonomy of sizes:
- Small: Single machine, single-threaded, synchronous, with no I/O or sleep
- Medium: Single machine, multi-threaded, asynchronous, localhost only
- Large: No constraints
- fDDD provides a pattern for implementing a high number of small tests protecting the most valuable business rules
- Use small tests to test derivers and invariants
- Use medium tests to test controllers
- Use partially applied controllers to keep medium-sized tests as small as possible
- Use large tests to test non-functional system factors such as scalability
- Readability can be improved by:
- Hermeticity: Remove environmental dependencies from tests
- No logic or control flow in tests
- Writing individual test cases to test an individual behaviour rather than functions
- Writing explicit DAMP test cases where relevant information is repeated rather than abstracted


