
Implementing the Outbox Pattern in Nodejs and Postgres

As applications scale, infrequent problems become significant. A network failure for 0.1% of requests is trivial at 1,000 requests per day, but a nightmare for customer support at 1,000,000 requests per day. This commonly happens when we have external dependencies following a successful operation. For example, if we want to send an SMS to a customer after they book an appointment then we will need to:
Insert their booking information into our database
Send a HTTP request to our SMS service provider
Let's pretend that it is really important that users receive this message, and receive these appointment confirmation messages in the order they were booked.
If we do both actions when a customer sends a request to our appointment/book endpoint, what happens if one fails but the other succeeds? Do we really want to cancel appointments due to latency or temporary errors from an external service? Will we hold open our database transaction until the SMS provider confirms or denies our request? Of course not. We should avoid letting an external service interfere with our application's key value proposition. Holding open database transactions for external services will lead to connection pool exhaustion in our service, especially when the third party's response times increase. Yuck!
How can we ensure that a text message is sent, and retried on failure, after an appointment is booked? By using The Outbox Pattern. This pattern is especially useful when messages must be dispatched in the correct sequence, such as the payment processor example in the image below.
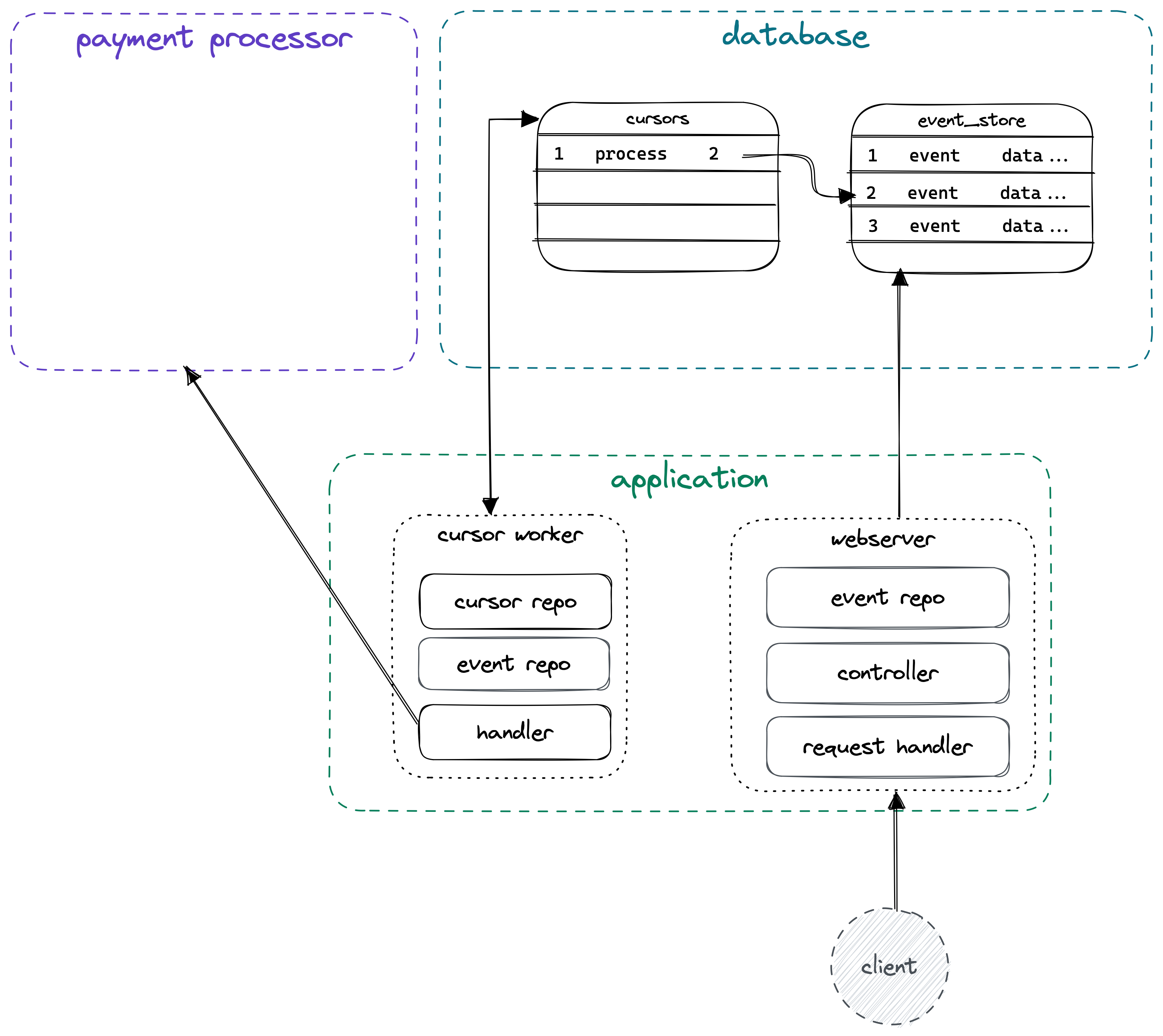
In this article, we will use the Outbox Pattern to ensure that an HTTP request to appointment/book only inserts a booking into our bookings table, while a background process sends an SMS message for each record in the table.
What are some of the implementation concerns our solution needs to address? They are:
Ensuring at least one message is sent per row.
Allowing this background process to run on multiple machines or processes without any risk of sending duplicate messages.
Ensuring messages are dispatched in the order appointments were booked.
Durability in terms of instance termination or process failure. I.e. messages aren't lost because a deployment occurred or a server crashed.
Let's get building!
Implementation
For our solution, we are going to use TypeScript, nodejs, pg, and Postgres with SKIP LOCKED. It will consist of:
A cursor repository that manages the transactions, locking, updating, and unlocking of a cursor
An outbox process that checks for new records to process
A handler that runs our action for each record
This approach allows us to create multiple outboxes or reuse the code for other purposes such as read model populators in an Event Sourced system.
The Cursor Repository
For our cursor repository, we want to allow callers to
Retrieve a cursor for an outbox if another process is not holding a lock on it
Update the cursor value
Unlock the cursor
We want the repository to support multiple processes, multiple cursors, and protect against a few common programmer mistakes. Let's start by defining the cursor table structure:
CREATE TABLE "cursor" (
"process_name" TEXT NOT NULL PRIMARY KEY,
"position" BIGINT NOT NULL DEFAULT 0,
"created_at" TIMESTAMP NOT NULL DEFAULT CLOCK_TIMESTAMP(),
"updated_at" TIMESTAMP
);
CREATE TRIGGER cursor_update_trigger
BEFORE UPDATE ON "cursor"
FOR EACH ROW
EXECUTE FUNCTION set_updated_at();
Let's insert a row for our SMS cursor
INSERT INTO "cursor"
("process_name") VALUES ('booking_sms_outbox');
Now let's write our cursor repository. We're going to instantiate a single instance of a cursor repository per process. Our solution will ensure that we never have multiple instances, and that we do not reuse an instance across multiple cursors. This is important because our repository needs to manage transactions and locking, but we want to hide these details from the caller.
type ProcessName = 'booking_sms_outbox' | 'foobar_populator';
type CursorRepository = {
getPositionWithLock(): Promise<number | undefined>;
setPosition(position: number): Promise<void>;
unlockCursor(): Promise<void>;
};
const CURSOR_REPO_MAP: Record<string, CursorRepository> = {};
export async function getCursorRepository(name: ProcessName): Promise<CursorRepository> {
if (CURSOR_REPO_MAP[name]) {
return CURSOR_REPO_MAP[name];
}
const client = await connectionPool.connect();
let isLocked = false;
CURSOR_REPO_MAP[name] = {
async getPositionWithLock() {
await client.query(`BEGIN;`);
const { rows } = await client.query(`
SELECT position
FROM "cursor"
WHERE "process_name" = $1
LIMIT 1
FOR UPDATE SKIP LOCKED
`, [name]
);
const cursor = rows.shift();
if (!cursor) {
await client.query(`ROLLBACK;`);
isLocked = false;
return;
}
isLocked = true;
return Number(cursor.position);
// casting bigint to number means this will work until 2^53-1 which is 9,007,199,254,740,991 -- if we inserted 10 million records per day it would take more than 2 million years to exceed this number.
},
async setPosition(position) {
await client.query(`
UPDATE "cursor"
SET "position" = $1
WHERE "process_name" = $2
`, [position, name]
);
},
async unlockCursor() {
if (isLocked) {
await client.query(`COMMIT;`);
isLocked = false;
}
},
releaseClient() {
client.release();
}
};
return CURSOR_REPO_MAP[name];
}
We've used memoisation to implement a functional singleton. This means the caller can safely call getCursorRepository('booking_sms_outbox'); multiple times but only instantiate one instance of the repository.
Our approach also prevents the caller from mixing up process names between calls. Additionally, we ensure that all calls for a cursor are made using an exclusive database connection. This is critical for our transaction and locking behaviour, just be aware that each of these processes will consume one connection per instance.
Now let's create the background process that uses this cursor repository.
Pro-tip: Set a sensible value for
idle_in_transaction_session_timeoutin the connection config used by the cursor. This will help prevent zombie connections from holding the lock indefinitely. You will also want to ensure you have process lifecylce hooks to unlock any locked cursors in the event of process exceptions, SIGTERM, and SIGINT.
Background Processor
We want to be able to start a background process that retrieves a cursor, gets new records, and handles each record sequentially. We're going to build a generic processor creation function, and then in the final step, we tie it all together with our handler.
type HasId = { id: number };
type Props<DbRecord extends HasId> = {
processName: ProcessName;
retrieveRecords: (position: number) => Promise<DbRecord>;
processRecord: (record: Record) => Promise<void>;
}
const CURSOR_POLLING_SLEEP_MS = 200;
export async function initialiseCursorProcess<DbRecord extends HasId>(props: Props<DbRecord>) {
const cursorRepo = await getCursorRepo(props.processName);
try {
const runTick = await createProcessTicker<DbRecord>(props);
while (lifecycle.isOpen()) {
const numProcessed = await runTick();
if (numProcessed === 0) {
await wait(CURSOR_POLLING_SLEEP_MS);
}
}
cursorRepo.releaseClient();
} catch (error) {
logger.critical('Terminating server: cursor process error', {
processName: props.processName,
error,
}); // we use structured logging
cursorRepo.releaseClient();
await lifecycle.close(1);
}
}
async function createProcessTicker<DbRecord>({
processName,
retrieveRecords,
processRecord,
}: Props) {
const cursorRepo = await getCursorRepository(processName);
lifecycle.on('close', async () => {
await cursorRepo.unlockCursor();
});
return async (): Promise<number> => {
const position = await cursorRepo.getPositionWithLock();
if (typeof position === 'undefined') {
return 0;
}
const records = await retrieveRecords(position);
let processedRecords = 0;
try {
for (const record of records) {
await processRecord(record);
await cursorRepo.setPosition(record.id);
processedRecords++;
}
} catch (error) {
logger.error('Could not process record', {
processName,
record,
error,
});
} finally {
await cursorRepo.unlockCursor();
}
return processedRecords;
}
}
A lot is going on here so let's break it down.
const runTick = await createProcessTicker<DbRecord>(props);
while (lifecycle.isOpen()) {
const numProcessed = await runTick();
if (numProcessed === 0) {
await wait(100);
}
}
cursorRepo.releaseClient();
First, we pass in our props and create the function that we want to run every tick. Then we start an infinite loop that will run until the node process receives a SIGTERM thanks to lifecycle.isOpen() using a lifecycle manager.
If nothing happened during each tick, we want to wait 100ms before running again. This prevents the process from flooding the nodejs event loop with callbacks in every tick. (wait is simply export const wait = async (ms: number) => new Promise(resolve => setTimeout(ms, resolve);).
After the while loop we call cursorRepo.releaseClient(); to close the connection to the database. This is required for await pool.end() to resolve during server shutdown.
What about that error handling?
} catch (error) {
logger.critical('Terminating server: cursor process error', {
processName: props.processName,
error,
});
cursorRepo.releaseClient();
await lifecycle.close(1);
}
In this case, something pretty drastic has happened, we want to log our errors and shut down the server as quickly as possible.
Moving on to the meat of our implementation, the process ticker and its creator function.
async function createProcessTicker<DbRecord>({
processName,
retrieveRecords,
processRecord,
}: Props) {
const cursorRepo = await getCursorRepository(processName);
lifecycle.on('close', async () => {
await cursorRepo.unlockCursor();
});
return async (): Promise<number> => {
// trimmed
In our createProcessTicker function we retrieve our cursor repo and include it in the closure space of our tick function that we define and return on the next line. I've also registered an onClose handler with our lifecycle manager to ensure any cursors release their locks before node exits.
Let's look at what happens in each tick.
const position = await cursorRepo.getPositionWithLock();
if (typeof position === 'undefined') {
return 0;
}
If we cannot retrieve a position it means another nodejs process, perhaps on another server, has a lock on this cursor at present. In that case, we want to return 0 since we won't be processing any records and wait at least 100ms before trying again.
const records = await retrieveRecords(position);
let processedRecords = 0;
try {
for (const record of records) {
await processRecord(record);
await cursorRepo.setPosition(record.id);
processedRecords++;
}
} catch (error) {
logger.error('Could not process record', {
processName,
record,
error,
});
} finally {
await cursorRepo.unlockCursor();
}
return processedRecords;
Now that we have some records, we simply initialise our counter then attempt to process each one and update our cursor position each time. We must make sure we always unlock the cursor when finished.
In the next tick, our process will re-attempt to process the record. This is handy if it failed due to reasons such as network error, but we will want to trigger alerts if we receive too many 'Could not process record' errors in a given period. It's also a good idea to measure how far behind the latest record each cursor is.
Time to bring this all together for our appointment booking SMS dispatcher.
Appointment Booking SMS Dispatcher
All of our process scaffolding is in place, now to build our SMS dispatcher.
export function initBookingSmsDispatcher() {
initialiseCursorProcess<Booking>({
processName: 'booking_sms_outbox',
retrieveRecords: bookingRepo.getNewBookingsSinceId,
processRecord: async (booking: Booking) => {
await smsProvider.sendBookingConfirmation({ booking });
},
});
}
The observant amongst you will notice the unawaited promise in initBookingSmsDispatcher. This is because we would be awaiting a while loop that only closes when the server is terminating. Accidentally awaiting a call to initialiseCursorProcess can cause the entire server to hang. So not only does initBookingSmsDispatcher nicely encapsulate all of our requirements for our SMS Dispatcher, but it also prevents us from accidentally deploying a goofy change failure bug.
For retrieveRecords we supply bookingRepo.getNewBookingsSinceId which is a repository function to retrieve all new rows since a given id. It might look something like this:
const INSERT_LATENCY_MS = 5;
async getNewBookingsSinceId(id: number): Promise<Booking[]> {
const isZero = id === 0;
const queryText = isZero ? `
SELECT * FROM "bookings" ORDER BY "created_at" ASC
` : `
SELECT * FROM "bookings"
WHERE "created_at" > (
SELECT "created_at" FROM "bookings"
WHERE "id" = $1
LIMIT 1
) AND "created_at" < (NOW() - INTERVAL '${INSERT_LATENCY_MS} milliseconds')
ORDER BY "created_at" ASC
`;
const { rows } = await client.query(
queryText,
isZero ? undefined : [ id ]
);
return rows.map(bookingRowToBooking);
}
This prevents the skipping of records that were inserted out of order. There is a race condition in Postgres where sequence numbers are granted to transactions concurrently. This means row 1234 might be inserted after row 1235. Looking up by created_at means we still get row 1234 if we look for events created after 1235.
We also avoid looking up records inserted within the last 5 milliseconds using AND "created_at" < (NOW() - INTERVAL '${INSERT_LATENCY_MS} milliseconds'). The reason for this is that when inserting many rows rapidly, there is no way to guarantee that each row will be available for lookup in the same order as their created_at timestamp.
For example, if I rapidly insert rows A, B, C, D, E, F and perform this lookup at the same time, Postgres could return rows A, C, F. But a moment later, the same query could return rows A, B, C, D, E, F. Why? Because rows B, D, and E may have a larger payload that takes longer to write to disk. Without this minor 5 millisecond latency, the cursor would jump to position F, and rows B, D, and E would never be processed.
Why 5 milliseconds? It depends on the size of your payloads. At SKUTOPIA, our largest payload is <20 kB, and we expect 5ms to work reliably up to ~2,000kB. For us, this is a very acceptable trade off.
Pro-tip: Consider a BRIN index for your
created_atcolumn, depending on the size of your table. Also consider usingCLOCK_TIMESTAMPinstead ofNOWfor yourcreated_atcolumn, in case the application ever inserts multiple rows in one statement or transaction.
When to Avoid the Outbox Pattern
The Outbox Pattern is not a replacement for a job system. This outbox process will halt if it encounters an unprocessable message. That's a design feature for some high-integrity use cases, but a flaw in others. It also trades off throughput for guaranteed ordering. If you need to send a lot of messages concurrently as fast as possible with no consequence in terms of failure, then this pattern is a poor fit.
For this article's SMS example, I would personally use a job system like pg-boss, and push back on our fictional PM's request for sequential SMS messages. Customer communication rarely needs an outbox implementation, it's typically programmatic systems that have trouble receiving messages out of order.
Conclusion
Now that you have the foundations for any cursor-based process to progress through a series of database records, you can use it for any outboxes you might want to create. It also works fantastically with Event Sourced systems, which is where we use it at SKUTOPIA. Each of our domain services uses event sourcing for their application state and publishes events to a PubSub topic for communication amongst services. We also use it to ensure usage events are sent to our payment processor. A critical use-case where at least once delivery and message ordering are both required.
Where might you use an outbox? Let me know in the comments.


